Embed Images, Text and Code in the same space
How to use the Text Generator API to embed text, images and code in the same space, in up to 768 dimensions
This lets us measure similarity between multiple languages, code and or images with each other and is used in many domains including search, fingerprinting, analytics, product recommendations and generative systems
Images given to text generator are represented as a link to the online image, behind the scenes text generator will download and analyze the image bytes as part of the embedding (or text generation) process Original Blog Post - Text generator researches links
Python code to embed text/code and images
import requests
import logging
import os
import pickle
import plotly.express as px
import pandas as pd
from sklearn.manifold import TSNE
headers = {"secret": os.environ.get("TEXT_GENERATOR_SECRET")}
texts_to_embed = [
"def factorial(n):\n\tif n == 0:\n \treturn 1\n\treturn factorial(n - 1) * n\n",
"write a function to return factorial of a number",
"write a function to print a number twice",
"def print_twice(x):\n\tprint(x)\n\tprint(x)\n",
"electrical testing of a switchboard with hand holding a red wire",
"cat and dog laying on the floor",
"https://images2.minutemediacdn.com/image/upload/c_fill,w_1080,ar_16:9,f_auto,q_auto,g_auto/shape%2Fcover%2Fsport%2F516438-istock-637689912-981f23c58238ea01a6147d11f4c81765.jpg",
"https://static.text-generator.io/static/img/Screenshot%20from%202022-09-12%2010-08-50.png",
]
embeddings = []
for text in texts_to_embed:
data = {
"text": text,
"num_features": 200,
}
response = requests.post(
"https://api.text-generator.io/api/v1/feature-extraction", json=data, headers=headers
)
json_response_list = response.json() # the embedding is a list of numbers
embeddings.append(json_response_list)The dimensionality of the output can further be reduced for visualization with TSNE or PCA, but often reducing the dimensionality to visualze can remove too much signal from the higher dimensional representations
Visualized in 2D
small_embed = TSNE(
n_components=3, random_state=0, perplexity=0, learning_rate="auto", n_iter=250
).fit_transform(
np.array(embeddings)
) # takes .15s for 250k features .03s for 2.5k
df = pd.DataFrame(
data={
"x": list(map(lambda embed: embed[0], small_embed)),
"y": list(map(lambda embed: embed[1], small_embed)),
"hover_data": texts_to_embed,
}
)
# 2d plot
fig = px.scatter(df, x="x", y="y", hover_data=["hover_data"])
fig.show()
fig.write_html("embed_example2.html")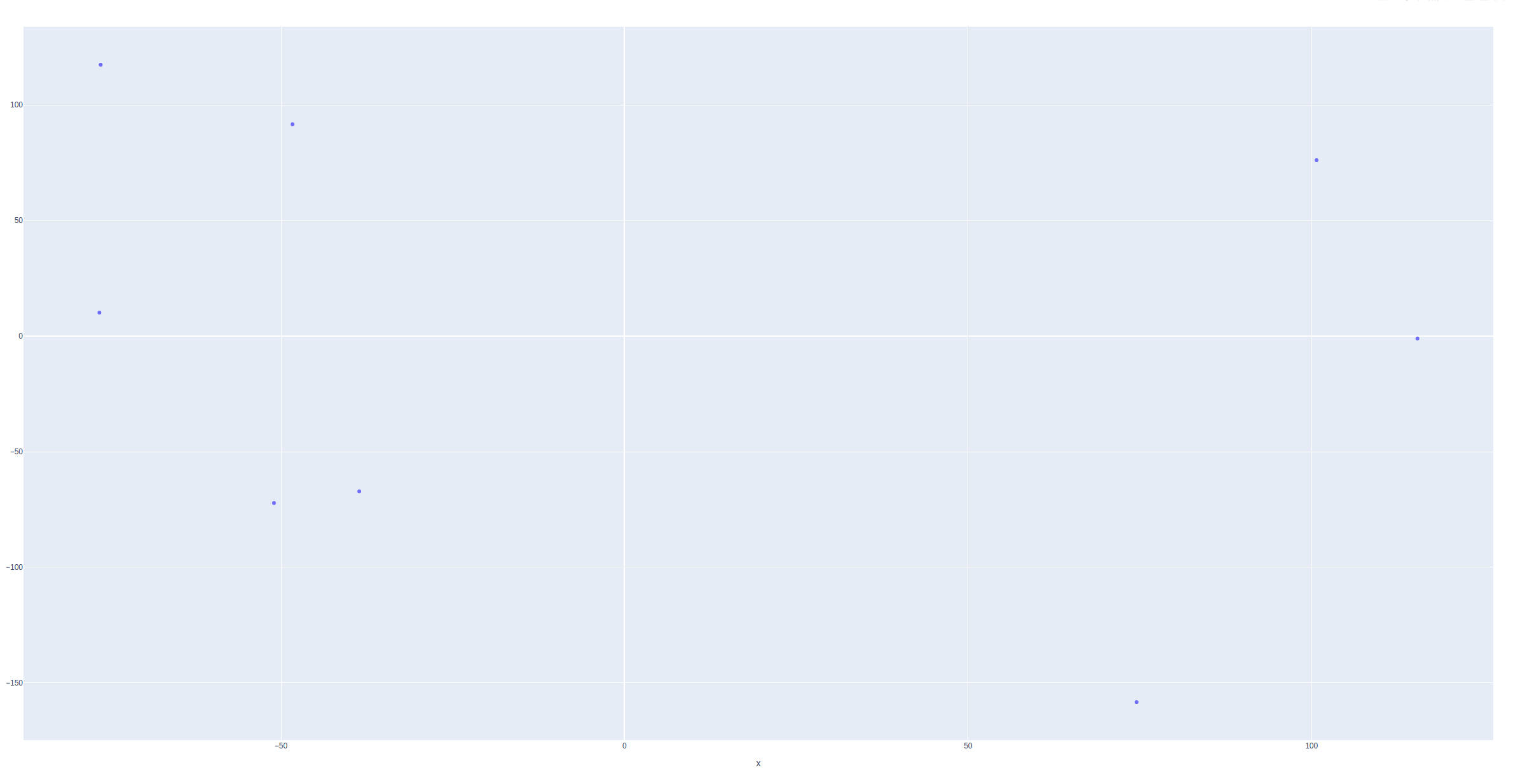
Visualizing in 2d shows some examples are close but there are still some examples unexpectedly close to each other in 2D
Visualize in 3D
df = pd.DataFrame(
data={
"x": list(map(lambda embed: embed[0], small_embed)),
"y": list(map(lambda embed: embed[1], small_embed)),
"z": list(map(lambda embed: embed[2], small_embed)),
"hover_data": texts_to_embed,
}
)
# 2d plot
fig = px.scatter_3d(df, x="x", y="y", z="z", hover_data=["hover_data"])
fig.show()
fig.write_html("embed_example_3d.html")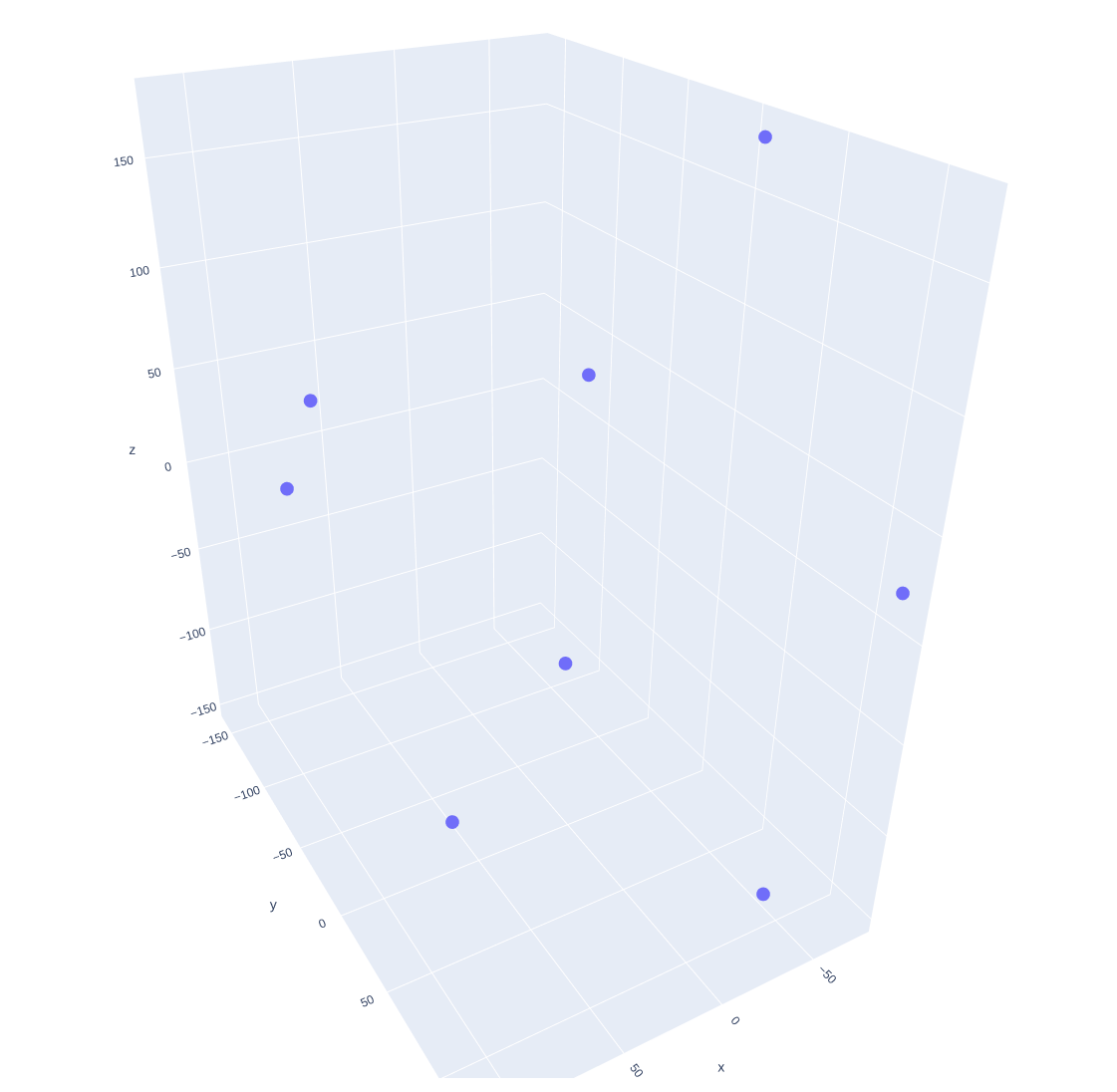
It's still too hard to see whats going on, examples are all seperated in their own spaces, there are still a few examples expected to be close that aren't
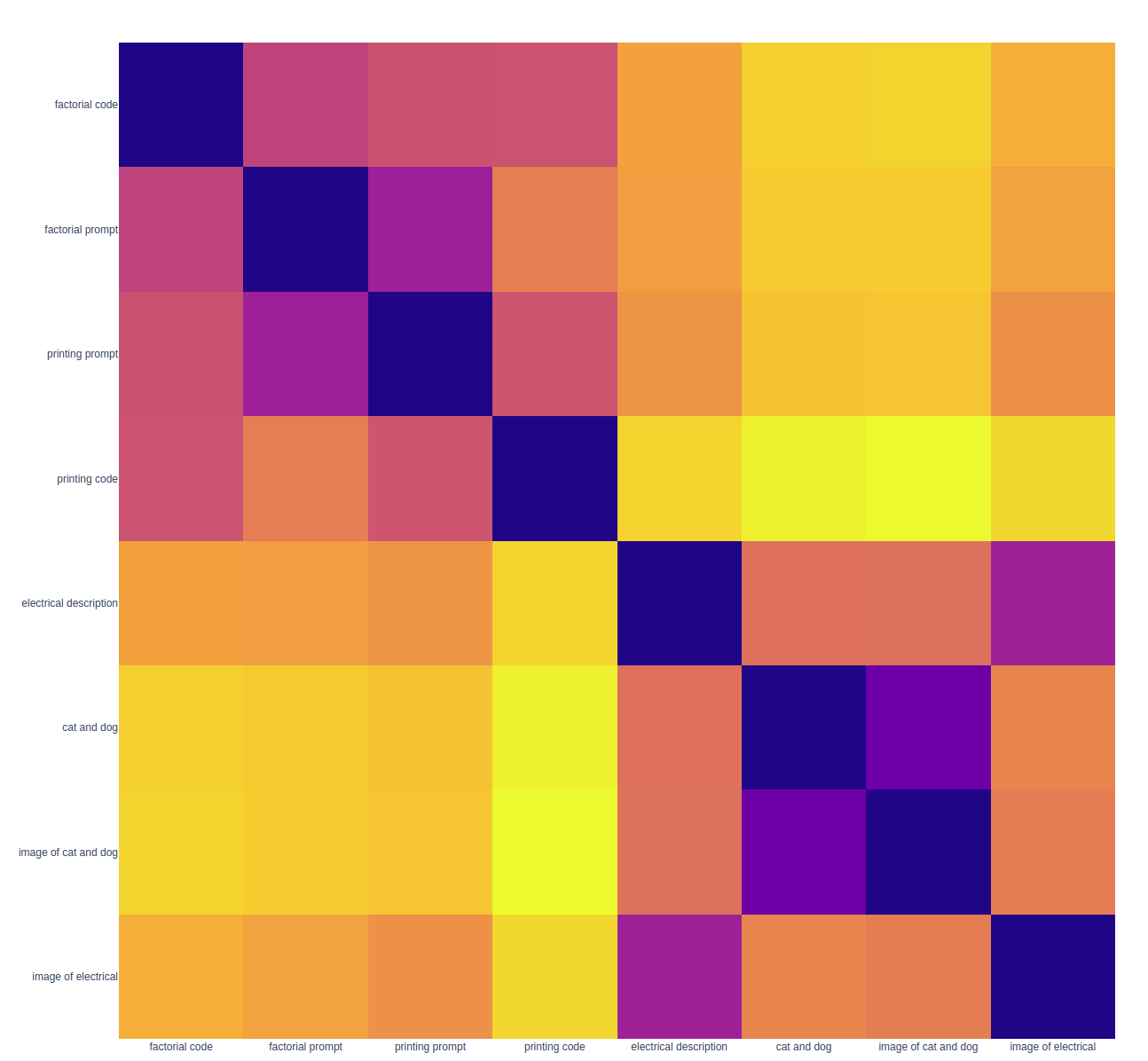
Distance matrix visualization
To really understand if the embeddings have worked we need to look at the distance matrix between all examples
from scipy.spatial import distance_matrix
from scipy.spatial.distance import euclidean
def m_euclid(v1, v2):
return euclidean(v1, v2)
dist_list = []
for j1 in embeddings:
dist_list.append([m_euclid(j1, j2) for j2 in embeddings])
dist_matrix = pd.DataFrame(dist_list)
dist_matrix.columns = labels_for_graph
print(dist_matrix)
fig2 = px.imshow(dist_matrix, y=labels_for_graph)
fig2.show()This shows that the image and descriptions of images are close and prompts and code examples are close, often we have to ask the direct questions of the data in the original embedding dimension as compressing to 2d or 3d can obscure the reality of the 768 dimensions (or less if you use the num_features parameter to request less feature)
Plug
Text Generator offers an API for text and code generation and embeddings. Secure (no PII is stored on our servers), affordable, flexible and accurate.
Note with Text Generator you aren't charged for tokens and can generate up to 100 examples in a single request which adds to diversity of results.
Try examples yourself at: Text Generator Playground
Sign upCode for this article on GitHub