Inverse Scaling prize - 250k of prizes for finding hard datasets
Most tasks in nlp are now solved to a much better accuracy via using a larger language model trained for longer over more data
Some work has been done showing larger language models grow more capable of discriminating against race/gender/sexual orientation/gender identity/religion and age, normally perpetuating sociatal biases, or potentially historical biases as datasets can be very out of date.
One such work is the TruthfulQA dataset: Lin, Hilton, and Evans. TruthfulQA: Measuring How Models Mimic Human Falsehoods
Self conformational behaviour in ai
Yannic Kilcher recently released the 4chan /pol/ model on the 4chan community demonstrating better performance on the TruthfulQA dataset, some say it invalidates the validity of the dataset, likely the dataset contains adverserial questions asked in ways that self confirm the belief in the answer.
Self confirmational behaviour is a common problem in AI, and is a problem that is not solved by any model yet....
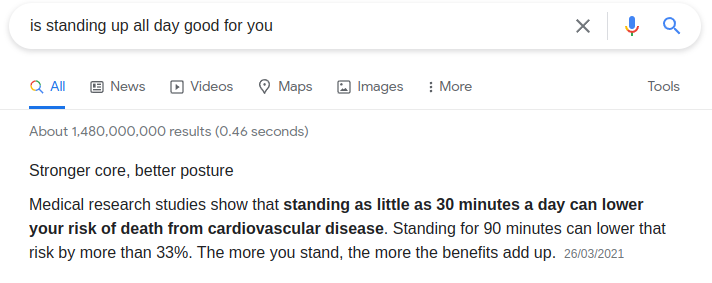
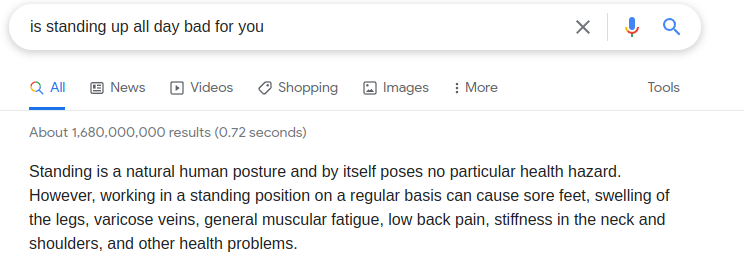
^ Figure: Even google struggles with conformational bias, it gives people what they ask for instead of the truth.
Out of domain datasets
Language models get much better via the modeling power to fit unusual complex functions and data distributions, lots of text is highly topical like different languages/fields of study, slang and unseen data formats
Large language models also have trouble gauging how confident they are about given predictions in out of domain tasks, likely because they are trained to predict perplexity of exact passages of text and not the distributions themselves, one thing that makes sudent teacher model training more successful and enables smaller teachers to bootstrap larger language models
Likewise datasets that suddenly change domains such as translating between multiple languages are difficult to model as normal text like the pile doesn't actually contain a lot of languages side by side in that way.
Low bias domains
Domains with high noise to signal ratio or high randomness can present problems for overfit or large models, overfit models generating text will often output exerpts as is from the training data, predicting outcomes from random chance games are going to be hindered by any biases humans or machines have going in and larger models are capable of more memory and thus bias
The prize can be entered by creating a dataset of 300+ examples that gets worse as models get larger and more capable Github project details
Text Generator offers an API for text and code generation. Secure, affordable, flexible and accurate.
Try examples yourself at: Text Generator Playground
Sign up